HOW ALGORITHMS ELEVATE YOU TO BE A NINJA DEVELOPER
First off, I’m going to talk a ton about Naruto, because it’s my ramen (seriously, if you haven’t watched this show, what are you even doing?). Now, when you hear “algorithms”, you might just think of complicated math problems or backend code magic. But guess what? Just as a shinobi needs their essential techniques, front end developers need algorithms. This article will dive into why every coder should get a grip on algorithms. There’s always that one person saying, “Why bother with algorithms? Aren’t they just…boring?” But here’s the deal: mastering algorithms for a developer is like perfecting the Rasengan for a ninja. It’s not just a skill, it’s a game changer. 🌀🖥️

1. Algorithms Are Everywhere
Before diving into the specifics of front end development, it’s essential to understand that algorithms are at the core of every computational process. Whether it’s sorting a list of names, filtering out specific data, or even just loading a web page, there’s an algorithm at work.
2. The Dynamics of Web Pages
Web pages are dynamic by nature. They contain elements that move, change, hide, and perform a host of other actions. Consider animations, responsive designs, and interactive elements like sliders or dropdown menus. Implementing these features efficiently requires a deep understanding of algorithms. To get the real time structure and content of a webpage is like trying to remember that billion-dollar unicorn company idea you dreamt of last night (again).
For instance, searching for all images on a page might seem like a simple task. However, consider a scenario where images are nested inside various containers, some are being loaded asynchronously, and others are hidden behind certain user interactions. An effective algorithm will ensure that searching and manipulation are optimized, reducing both time and resource consumption.
3. Performance Optimization
The performance of a website is paramount. Slow loading websites can deter users and affect search engine rankings. While many factors influence a site’s speed, inefficient algorithms can significantly slow down page rendering and interactivity.
By employing optimal algorithms, developers can ensure that web pages render faster, animations play smoothly, and user interactions are seamless. This not only provides a better user experience but can also impact business metrics like conversion rates.
4. A World Beyond the Backend
There’s a common misconception that the backend is where all the ‘serious’ computation happens, and the frontend is mainly about presentation. But as web applications become increasingly sophisticated, more logic is pushed to the client side. Frameworks like React, Vue, and Angular allow developers to build highly interactive single-page applications (SPAs) where the bulk of the data processing happens in the browser. Here, efficient algorithms play a pivotal role in ensuring a smooth user experience.
5. Enhancing Problem-Solving Skills
A sound grasp of algorithms enables developers to approach problems methodically. When faced with a challenge, they can break it down into smaller parts, solve each part using an appropriate algorithmic strategy, and then combine the solutions. This structured approach to problem-solving is invaluable not just in coding but in many other aspects of a developer’s job.
A notable example is Richard Feynman’s (one of my heroes) involvement in the investigation of the Space Shuttle Challenger disaster. Instead of getting bogged down by intricate theories, he famously demonstrated the O-ring’s vulnerability to cold by simply compressing a sample of the material in a clamp and immersing it in ice-cold water. The material failed to spring back, illustrating its compromised resilience at low temperatures. Feynman’s approach underscores that sometimes, the essence of problem-solving lies in distilling complexity to its simplest form, a core tenet of algorithmic thinking.

Let’s discuss a practical example which is one of my favorites topics: Web scraping. It is a concept that can touch both frontend and backend development, but they are traditionally more associated with backend processes. Let’s delve into their relationships with both frontend and backend development.
Web scraping refers to the extraction of data from websites.
This typically involves:
- Fetching the Web Page: This usually requires sending an HTTP request to the website’s server and obtaining the HTML response, which is a backend operation.
- Parsing the Data: Once the HTML response is received, the data of interest is extracted by parsing the HTML content. This can be done using various libraries or tools designed for this purpose.
- Storing the Data: After extraction, the data is often stored in databases or files, another backend operation.
While the actual parsing can technically be done in the frontend using JavaScript and DOM manipulation functions, in practice, scraping is largely a backend task because of the need to manage HTTP requests, handle storage, and often process large amounts of data.
The knowledge of HTML structure and how to traverse it is essential to both web scraping and web crawling. This understanding primarily pertains to the frontend domain, but it becomes highly relevant when applying these skills in the context of scraping, which often operate in backend systems.
How frontend domain knowledge would help in web scraping tasks?
1. Understanding HTML Structure:
When it comes to web scraping, the structure of HTML determines how data can be extracted. Here’s why understanding the HTML structure is crucial:
- Semantic Meaning: HTML tags provide semantic meaning about content. Knowing the difference between <div>, <article>, <nav>, and other tags can give context to the data being scraped.
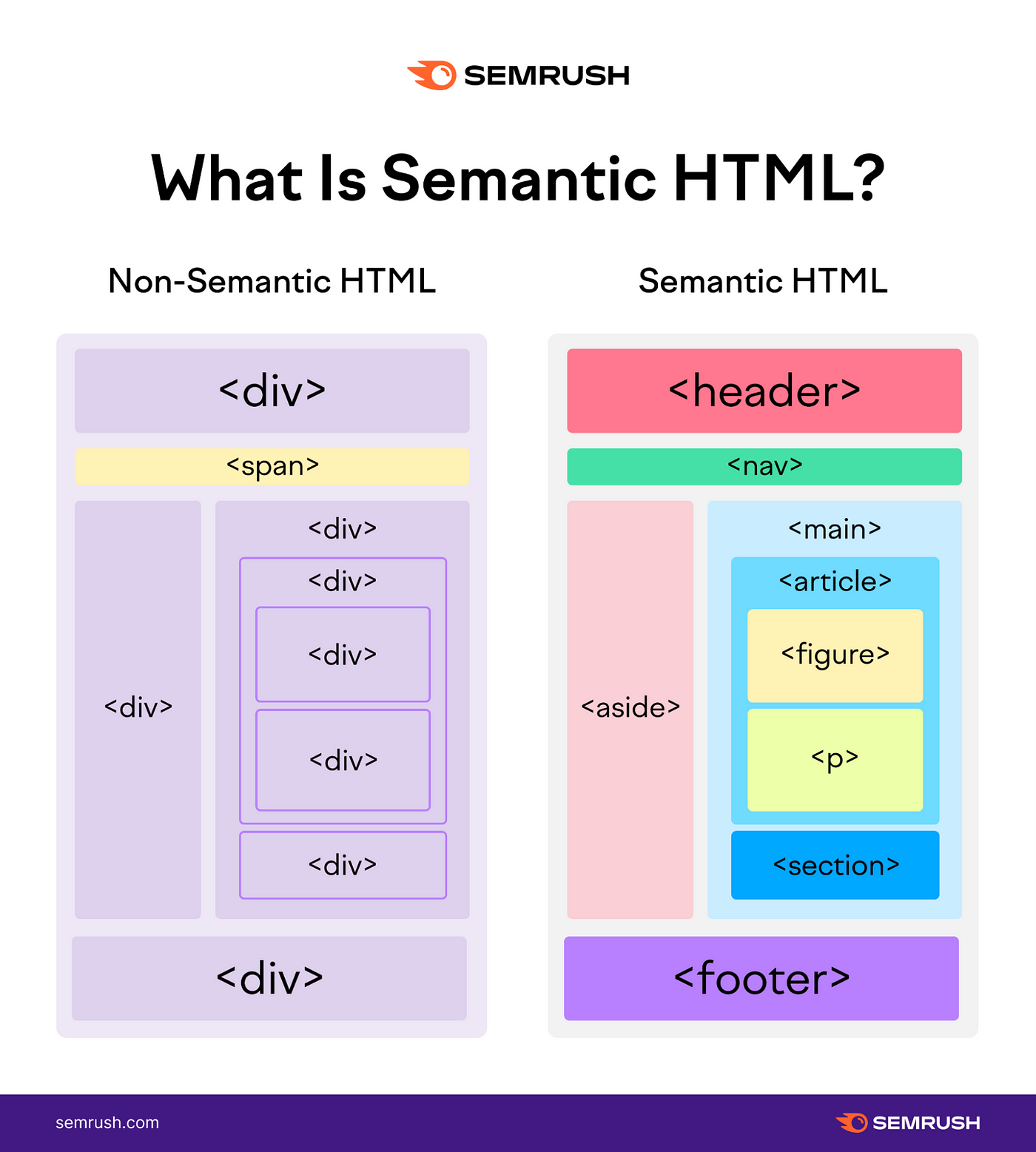
- Data Hierarchy: Elements in HTML are nested, creating a hierarchical relationship between them. Being familiar with this hierarchy allows one to locate data more precisely.
- Attributes & Metadata: Many times, essential data or links aren’t just within the tags but also in attributes, like href in <a> tags or src in <img> tags. Knowing where to look is pivotal for efficient scraping.
2. Traversing the HTML Tree:
The hierarchical nature of HTML makes it a tree structure. Traversing this tree is a foundational aspect of both frontend development and web scraping:
- DOM Manipulation: Frontend developers utilize DOM (Document Object Model) manipulation techniques to interact with web pages using JavaScript. Tools like document.querySelector or libraries like jQuery offer methods to navigate and modify the DOM.
- Scraping Libraries & Tools: Backend processes involved in scraping use specialized libraries like Beautiful Soup (Python), Cheerio (JavaScript), or Scrapy (Python) to traverse the HTML tree. These libraries provide methods that mirror frontend DOM manipulation techniques but are designed for backend processing. The user provides selectors or patterns, and the library fetches the relevant data.
In Application:
To effectively extract data using web scraping, one might do the following:
- Inspect the Web Page: Using browser developer tools, a developer or data scientist inspects the structure of the webpage to identify how data is organized and which tags/attributes contain the desired information.
- Craft Selectors: Based on the inspection, they craft CSS selectors or XPath expressions to target the data of interest.
- Use a Scraping Tool: The crafted selectors are then used in conjunction with a scraping library or tool to programmatically extract data.
Here is a real life example which is, scraping web pages for new products and their details like prices and discounts. I needed to see if the a tag (a link) is inside a div and that the a tag has children that are image tags (which means that the image is clickable and probably a real product) . We can look for the images properties like minimum width of 70px.

This example is a composite of several requirements that involve both DOM traversal and property checks. Let’s break down the requirements first:
- The <a> tag should be a descendant of a <div>.
- The <a> tag should have children that are <img> tags.
- The image should have a width property of at least 70px.
Algorithmic Approach:
- Traverse the entire DOM.
- If a node is an <a> tag and its closest parent <div> exists:
- Check its children.
- If one of its children is an <img> tag and has a width of 70px or more, store the <a> tag.
Code example for such task in JavaScript:
function findProductImageLinks(node) {
const result = [];
if (!node) return result;
if (node.tagName === 'A' && node.closest('div')) { // Ensuring <a> tag is a descendant of a <div>
for (let child of node.children) {
if (child.tagName === 'IMG' && child.width >= 70) { // Checking for <img> child with a width of 70px or more
result.push(node);
break; // Once a valid <img> is found, no need to check the remaining children of this <a> tag
}
}
}
for (let child of node.children) {
result.push(...findProductImageLinks(child));
}
return result;
}
// Usage:
const productImageLinks = findProductImageLinks(document.body);
console.log(productImageLinks);
Approaching this problem in a non-algorithmic way might employ redundant checks, not making full use of available browser methods, or make assumptions that could lead to errors (but maybe it’s a good thing).
let’s see a naive approach:
- Search for all <a> tags on the page.
- For every link, look if it has any children.
- If it has children, iterate over all elements on the page and see if any of them are <div> elements containing the <a> tag in question.
- For each child of the link, check if it’s an image. If it is, get its width attribute.
- Compare the width attribute as a substring to see if it’s greater than or equal to 70px.
function poorlyFindProductImageLinks() {
const allLinks = document.querySelectorAll('a'); // Get all <a> tags
const results = [];
for (let link of allLinks) {
const allDivs = document.querySelectorAll('div'); // Get all <div> tags for every link (highly inefficient!)
let isInsideDiv = false;
for (let div of allDivs) {
if (div.innerHTML.includes(link.outerHTML)) { // Checking if <div> contains the <a> tag by comparing their HTML (prone to errors)
isInsideDiv = true;
break;
}
}
if (!isInsideDiv) continue;
for (let child of link.children) {
if (child.tagName === 'IMG') {
const widthStr = child.getAttribute('width'); // Assuming width is always explicitly set as an attribute (might be unreliable)
if (widthStr && parseInt(widthStr) >= 70) {
results.push(link);
break;
}
}
}
}
return results;
}
// Usage:
const badProductImageLinks = poorlyFindProductImageLinks();
console.log(badProductImageLinks);
Issues with this Naive Approach:
- Redundant DOM Queries: We’re querying all <div> elements for every <a> tag, which is wasteful.
- Unreliable Checks: Using innerHTML.includes() to check if a <div> contains an <a> is error-prone. This method can have false positives if the exact HTML string is present elsewhere.
- Assumptions: Assuming the width of the image is always available as an explicit attribute is not reliable. CSS or inherent image dimensions might determine the real displayed width.
- Performance: This approach is not optimized and would be very slow, especially on pages with a significant number of elements.
To illustrate the differences in time and space complexity using seconds for time and MBs for space, instead of O notation ,I’ll make some assumptions. These values are hypothetical and will vary significantly based on actual data, browser performance, hardware, and more.
Here are the assumptions:
Average Page Details:
- Number of <a> tags (n): 100
- Number of <div> tags (d): 1000
- Average length of HTML content (l): 100 characters
- Average number of children for an <a> tag: 5
Execution Time Assumptions:
- Basic operation (like accessing an element or checking a property): 0.00001 seconds (10 microseconds).
- String matching operation (like innerHTML.includes()): 0.0001 seconds per character.
Space Requirement Assumptions:
- Storing a reference to an element: 0.1 MB (this is a high overestimate to emphasize space usage)

But first we need to understand very important concepts like space and time complexity. We can’t discuss algorithms without them.
Space Complexity: Imagine you have a bookshelf, and you want to store your books on it. The space complexity would be how much of that shelf space gets used up based on the number of books you have. If you need an entire new shelf for every single book (which would be silly), that’s high space complexity. But if all books fit on one shelf regardless of how many you have, that’s low space complexity.
Time Complexity: Now, think about finding a book on that shelf. If you can find any book instantly, no matter how many books you have, that’s low time complexity. But if it takes longer to find a book as you add more to the shelf, that’s high time complexity.
In the bookshelf analogy,
O(n) (read as “Order of n” or simply “O of n”) represents a situation where the time or space required increases linearly with the number of books (n).
In essence, O(n) means that the resource requirement (be it time or space) grows directly in proportion to the number of items (books, in this case) you’re dealing with.
So, why isn’t this always a good way to examine things?

Well, in the real world, not all situations are equal. Let’s say you have a method that’s super quick (low time complexity) for searching among 10, 100, or even 1,000 books. But when you reach a million books, it becomes horrendously slow. However, another method might be slightly slower for 1,000 books but much faster for a million.
If you judged only based on the performance with 1,000 books, you’d pick the first method. But if you know you’re going to deal with huge libraries, the second method is clearly better. This is why time and space complexity can’t be the only factors you consider. Sometimes, real-world context and expected scale play a crucial role in choosing the right approach.
Now, using the above assumptions, let’s calculate and then construct a table for both the algorithmic and naive approaches.
So what let’s get back to our example
Time Complexity of the algorithmic Approach:
O(n) time: 100 × 0.00001 = 0.001 seconds
Naive Approach:
O(n×d×l) time: 100 × 1000 × 100 × 0.0001 = 1 second
Space Complexity:
Algorithmic Approach:
Maximum space:
O(n+d) = 100 + 1000= 1100 references
Size:
1100 × 0.1 = 110 MB
Naive Approach:
Maximum space:
O(n+d) = 100 + 1000 = 1100 references
Size:
1100×0.1 = 110 MB
Both approaches have a similar space complexity because they store references to DOM elements, and our assumptions about storage size are consistent across both, but we will look at an improvement for that later.

This table demonstrates that while the space complexity in terms of storage may not differ significantly between a good algorithmic approach and a naive one (given our assumptions), the time complexity difference can be vast. A one-second delay in processing, especially in real-time interactions, can be noticeably detrimental to user experience.
Let’s implement the ideas to optimize the space usage in the context of the web scraping example where we’re identifying specific <a> tags within <div> elements. We’ll show a more efficient way of extracting and storing relevant data and compare the results.
const relevantLinks = [];
document.querySelectorAll('div a').forEach(link => {
if (link.querySelector('img[width="70"]')) {
// Only store the href attribute to save space
relevantLinks.push(link.href);
}
});
Optimizations:
- By using the selector ‘div a’, we immediately narrow down to only <a> tags within <div> elements, which reduces the data we initially process.
- Instead of storing the full DOM references of relevant <a> tags, we only store their href attributes. This significantly reduces the amount of space each stored item consumes.
Let’s break it down again

Average number of <a> tags in <div> elements (n): 100
Average string length of href attributes: 100 characters
Space required to store a character: 0.000002 MB (2 bytes for UTF-16 encoding in JavaScript)
Storing a reference to a string (like href): 0.0001 MB (very high overestimate)
Space Requirement:
Storing href attributes for all relevant links: n * average string length * space per character = 100 * 100 * 0.000002 MB = 0.02 MB
Storing references to these strings in the relevantLinks array: n * space per reference = 100 * 0.0001 MB = 0.01 MB
Total space = 0.02 MB + 0.01 MB = 0.03 MB

Because we are on the actual link and not the whole object, storing only the href attribute of each link rather than the full DOM reference, we use significantly less space. The href attribute is a string, and strings are much lighter in memory than entire DOM nodes with all their properties and methods.
We can also narrow down to only <a> tags within <div> elements so we process fewer elements and subsequently store less data. When we store only the necessary data (in this case, the href attributes), the space usage is minimized.
The difference between the algorithmic and non-algorithmic approaches is staggering, both in terms of time and space. In terms of time, the algorithmic approach is 1,000 times faster (0.001 seconds vs. 1 second), which translates to a 99.9% improvement. Now, when we look at space, while our initial comparison showed both strategies using 110 MB, the optimized approach only requires 0.03 MB. This marks a substantial reduction of over 99.97% in space. In practical terms, this means that for every 1,000 operations, what took almost 17 minutes with the naive approach would now take less than a second with the algorithmic one, and instead of requiring roughly 11 GB of space (over 10 operations), we would need just about 0.3 MB. The magnitude of this efficiency cannot be overstated.

The leap in performance after optimizing your code is sort of like going from trying to move a paper ball across a table with a measly nose blow (we’ve all been there) straight to busting out a Shuriken Rasengan.

Conclusion
To sum it up, algorithms are everywhere and by being aware of them we can make our web applications to be more efficient, responsive, and user friendly. As web technologies continue to evolve, the importance of understanding and effectively implementing algorithms will only increase. Whether you’re just starting out or are an experienced developer, enhancing your algorithmic knowledge can propel you to the forefront of modern web development.


Pingback: How to Make Your JavaScript Code Blazingly Fast With This One Simple Trick! 🔥 - learningjournal.dev