In my previous blog post I mainly wrote about the motivation, setting goals, and how to stay focused while learning, in this article we are going to discuss more technical aspects.
As a developer, you might have come across countless articles with headlines screaming, “X method is the best way to do Y!” or “Stop using X and start using Y!”. In a realm perpetually blossoming with new JavaScript methods, it’s easy to find yourself confused with all the different suggestions and feeling the pressure to keep up. It’s a common experience, particularly amongst junior developers, but also, seasoned ones are not immune. The fear of missing out (FOMO) is real and can be overwhelming.
The philosophy of this article is inspired by a valuable lesson from my journey as a martial arts student. Having practiced Karate, Aikido, and Muay Thai, I have come to understand that there isn’t such a thing as the “best” martial art. Just take a look at the world of Mixed Martial Arts– it’s not an homage to a single martial art, but a symphony of the most effective techniques from a myriad of disciplines.
The best martial artists, like an experienced MMA fighter, know how to utilize the best parts from each discipline: the control and ground techniques from Wrestling, the complex submission moves from Brazilian Jiu-Jitsu, the precise and powerful striking from Boxing and Muay Thai. This blend creates a comprehensive fighter who can handle and adapt to whatever comes their way.
Likewise, in the world of programming, the ‘best’ method or tool doesn’t exist as a standalone entity. Rather, it’s about picking the right tool, or combination of tools, that best suits the problem at hand. This understanding allows you to become a comprehensive programmer who can juggle between different techniques and apply the most effective solution depending on the context.

So, are you ready to step into the coding dojo? Let’s delve into the nuances of JavaScript and explore the strengths, weaknesses, and applicabilities of some common methods for finding a specific word within a string.
The bold headlines of the articles I’ve mentioned might reel you in, but then they leave you hanging, with a fresh set of questions. What’s the context? What factors should I consider? Is there a perfect for any task??
Spoiler alert: there isn’t a one-size-fits-all solution. These often absolute and binary declarations I see floating around remind me of those simplistic movie villains, whose only character depth is, “Well, he’s evil.” What these assertions lack is depth, context, and most importantly, nuance.
That’s why, in this article, we’re going to take a different route. We’re not just going to scream out a method, drop the mic, and exit stage left. Instead, we’re going to scrutinize, analyze, and contextualize. Our focus will be on identifying the “right” method based on specific circumstances and considerations.
Why, you ask? Because in real-world scenarios, you’re not just coding in a vacuum. You’re navigating an intricate maze of factors like performance, readability, maintenance, compatibility, and more. And your trusty guide through this labyrinth? It’s understanding the strengths, weaknesses, and quirks of your tools.
Today, our exploratory lens is focused on JavaScript — more specifically, on the diverse ways to check if a string contains a specific word. Together, we’ll investigate these methods, not in isolation, but in the context of a variety of scenarios and requirements.
Let the journey begin!
We delve into four common JavaScript methods used to find whether a string of words includes a some word.
This is a simple and straightforward method. It’s a solid choice when all you need is to check whether the string contains a specific substring. However, if your requirements extend to knowing the position of the found substring or employing regular expressions, this method might not suffice.
This method shines when you need to know the starting index of a substring. It’s fast and enjoys wide browser compatibility, including older browsers. That said, for a simple boolean result or regular expression usage, other methods could be more beneficial.
String.prototype.match() — Regular expression (RegExp):
Regular expressions come in handy when the search involves complex patterns within strings. Their ability to match complex patterns and provide case-insensitive searches is impressive. But, be warned! Regular expressions can be tricky to understand and maintain. If your needs are simple, there are other, more approachable methods available.
Split string and check each word:
When it’s crucial to treat whole words individually and not as part of other words, this method wins. For instance, it ensures that “location” and “relocation” are treated as different words. However, the operations involved could lead to performance issues with very long strings. It’s also case-sensitive and does not provide the position of the found word.
Let’s take a comprehensive look at all these methods, their trade-offs, and their appropriate use-cases, presented in a clear and concise table.
Code examples:
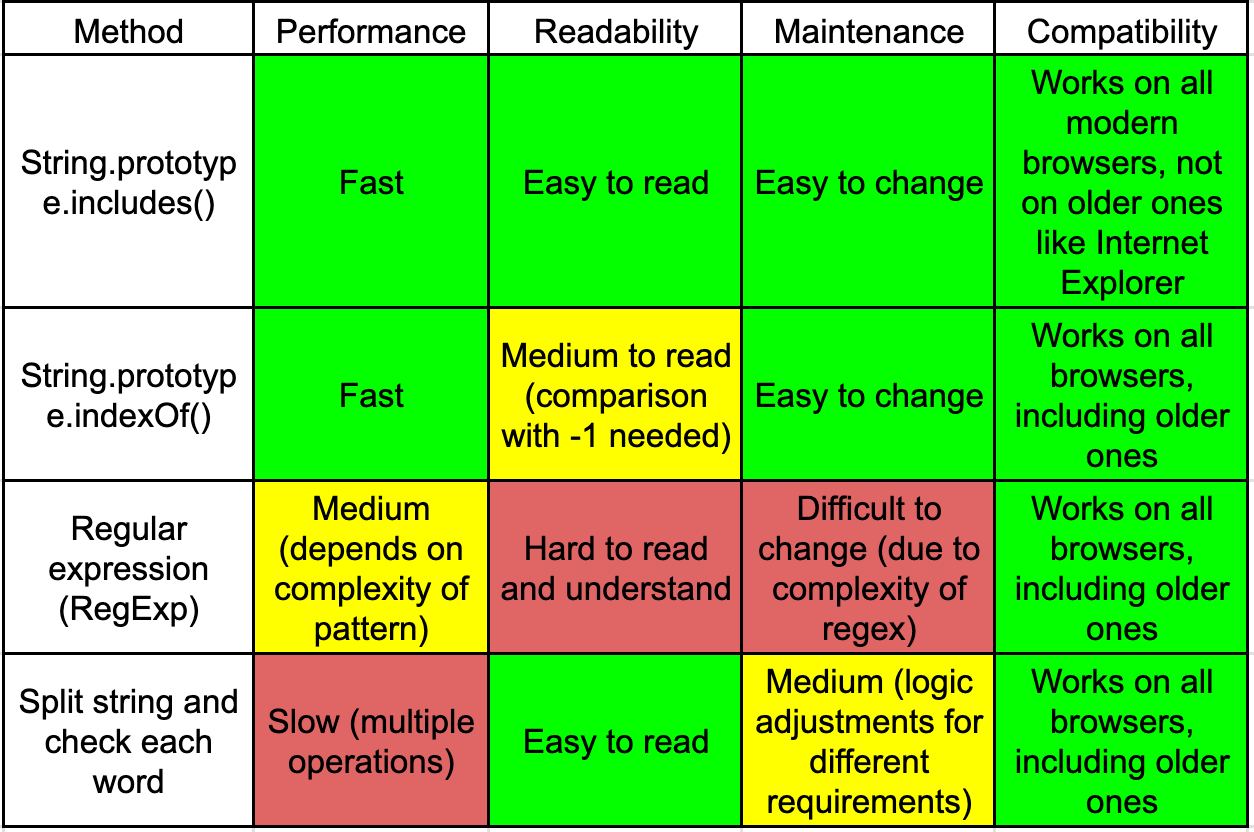
String.prototype.includes() method:

This method, as the name suggests, check if a string includes another string.
String.prototype.indexOf() method:
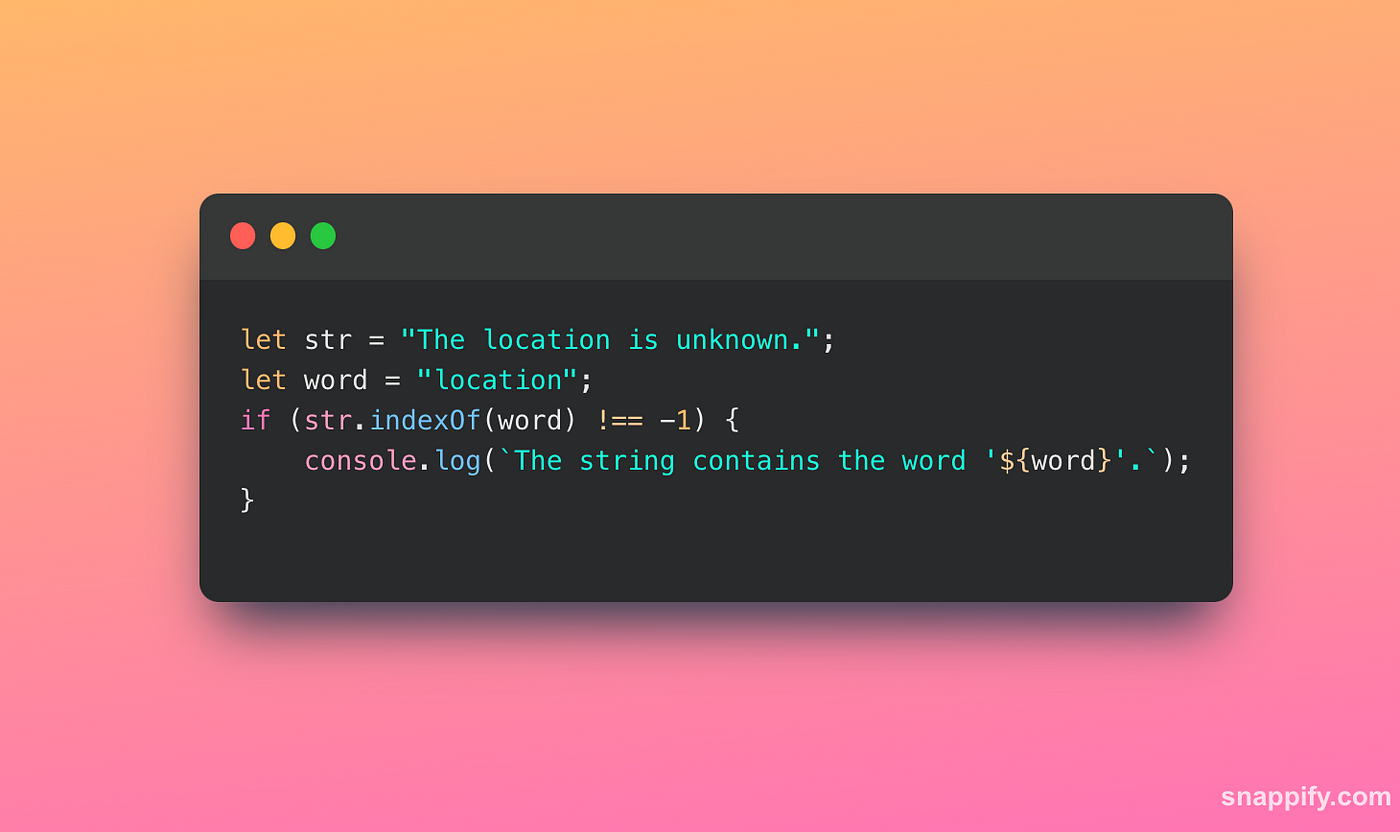
This method returns the position of the first location of a specified string in another string. If the word is not found, it will return -1.
Regular expression (RegExp):
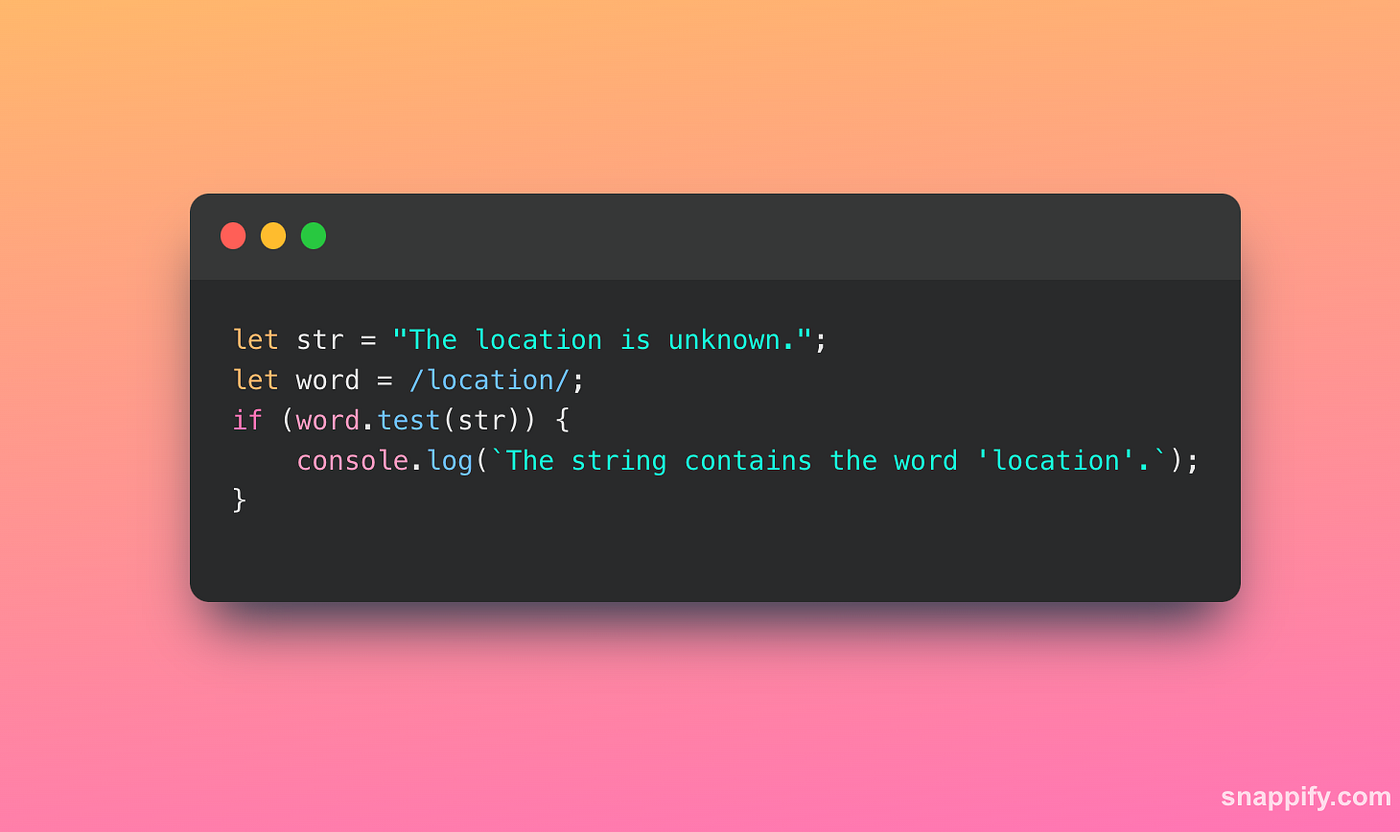
You can use a regular expression to search for a word in a string.
Split the string into words and check each word:
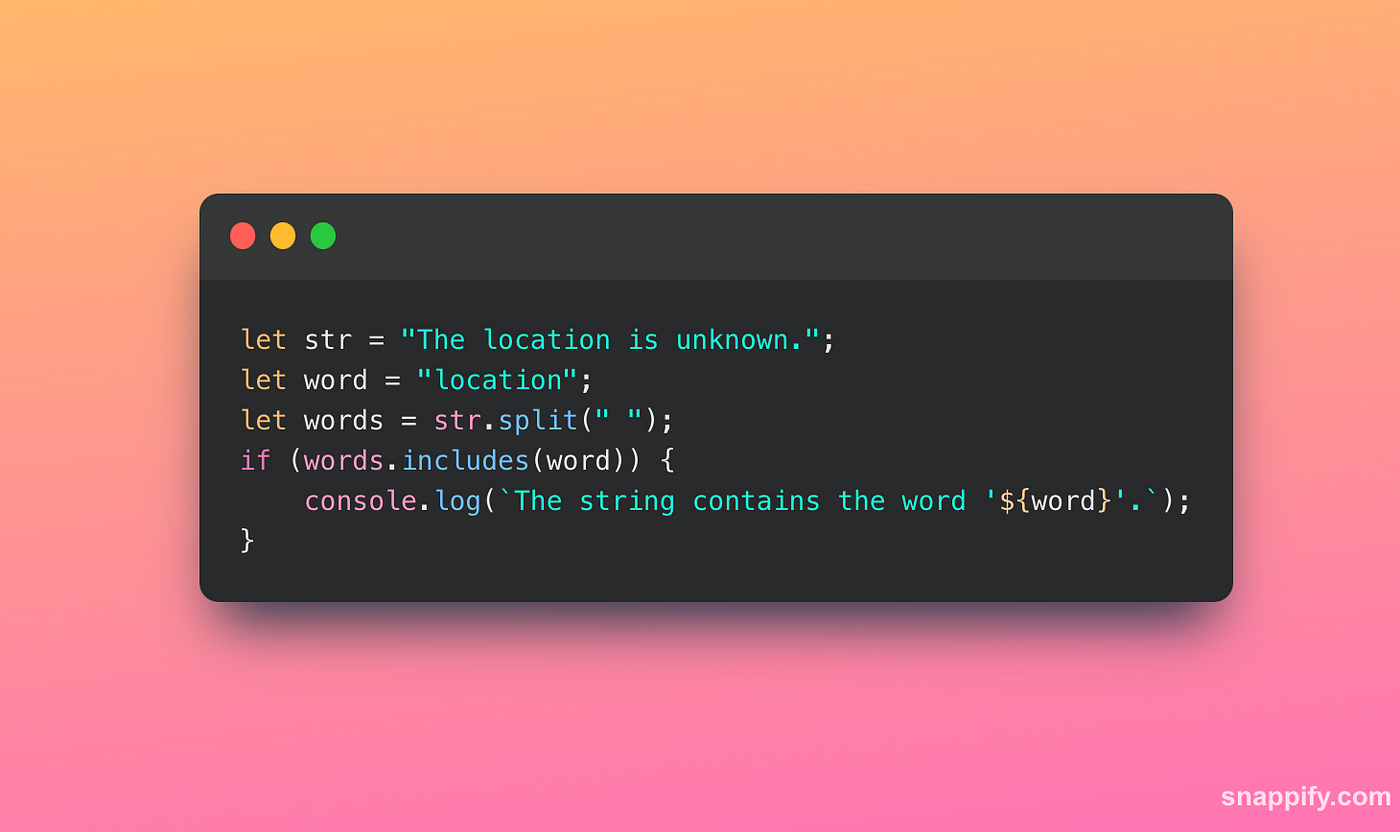
This method can be used when you want to check for whole words and not substrings. More on this approach later.
While at face value, String.prototype.includes() might seem like the most logical choice due to its simplicity and speed, it is not universally compatible, specifically with some older browsers. If the demographics of your user base largely lean towards older Android browsers, using includes() could lead to unintended issues, as it’s not supported there.
Let’s say, due to some unfortunate, tragic turn of events, the majority of your service’s users are stuck in the digital stone age, clinging to their older Android browsers. As a developer, even writing this makes me very sad.
Now, it’s easy to think, “Oh, they’re just a tiny fraction of all internet users! Surely they don’t count that much?” But guess what? They’re YOUR users. They’re the brave souls venturing into your application’s digital wilds, equipped with nothing but their trusty dial-up phones.
But jokes aside, every user is important, and their experience matters! It’s our job to make the digital journey as smooth as possible.
The website caniuse.com is a valuable resource to check feature support across different browsers. The includes() method has support in most modern browsers but lacks in Internet Explorer and older versions of Android’s browser.
Therefore, under such circumstances, String.prototype.indexOf() would indeed be a safer choice. It might be a tad more complex due to the need for comparison with -1, but it assures broader compatibility, catering to your unique user base.
Thus, the decision-making process should not only involve the technical aspects of the different methods but also an understanding of your user demographic and their technological context.
But….. readability is an important factor to consider when writing code, especially when working in a team. String.prototype.indexOf() is a very useful method, but its use might not be intuitive to someone new to JavaScript or unfamiliar with this quirky method.
The indexOf() method in JavaScript returns the position of the first time he finds the request value in a string. This method returns -1 if the value is not found.
So, when you see string.indexOf(‘somestring’) !== -1, this is checking whether the ‘string’ is present in ‘somestring’. If ‘string’ is not present, indexOf() returns -1, and therefore the expression evaluates to false. If ‘string’ is present, indexOf() returns the position in the string, for exmple at the beginning it would be 0, so anything but -1, so the entire expression will be true.
Here’s a breakdown:
string.indexOf(‘string’) checks the position of ‘string’ in ‘somestring’. If ‘string’ is found, it returns the position (a non-negative integer), and if not found, it returns -1.
!== -1 is a comparison to check if the result of indexOf() is not equal to -1. If it’s not -1, that means ‘string’ was found in ‘somestring’.
So, when you see string.indexOf(‘somestring’) !== -1, it’s effectively checking whether ‘string’ is present in ‘somestring’.
Abstracting this into a function can make your code cleaner and more readable. Let’s say we have a function named doesIncludeString() that accepts two parameters: the original string and the substring to search for. Here’s how you could implement it:

If the ’substring’ is present in the ‘original’ string, this function will return true; otherwise, it will return false. This method has the advantage of encapsulating the indexOf() logic and offering a more user-friendly and self-explanatory interface for determining whether a string contains another string. In this manner, the function name clarifies the purpose, enhancing readability and maintainability.
Here’s how you’d use it:
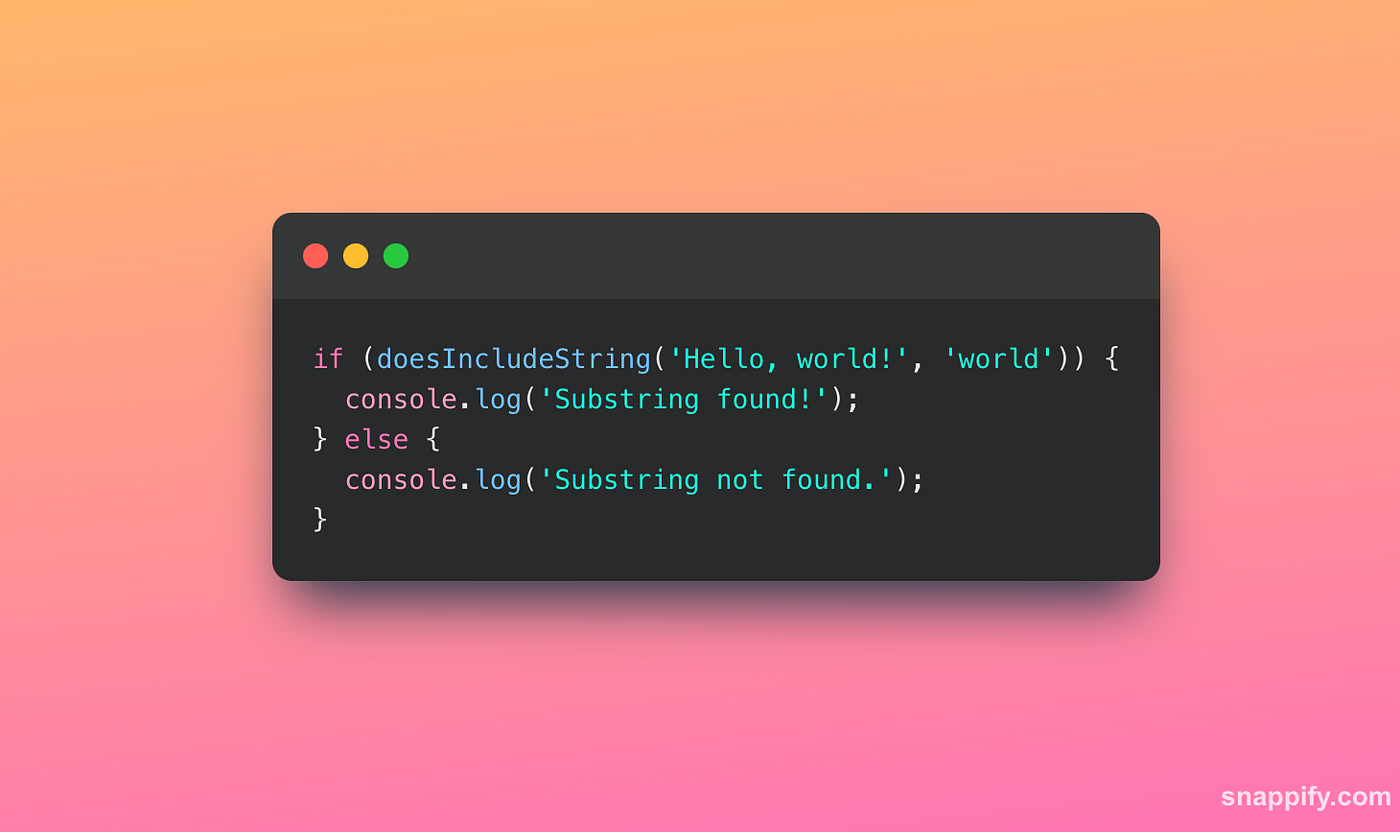
This code snippet is easier to read and understand, even for developers unfamiliar with the intricacies of the indexOf() method and of course you can add more validations to it and still keep the code readable and maintainable.
We’ve made it to the finish line! But wait, there’s always more. As you’re probably thinking, “Just when I thought I was out… they pull me back in!” In the dynamic world of programming, there’s always another layer to peel back, another angle to explore. But that’s the beauty of it, isn’t it?
Let’s say that the string you are getting is such as ‘userIdInfo=SecretAgent’ but you are looking for the string “userId=12345678”. Now, if you would use indexOf(), it can turn into quite a conundrum. The indexOf() function starts at the beginning of the string and returns the index of the first time is encounters the string. So in our case, indexOf() would return true! and you will make decisions based on this. You can almost hear the dramatic music as our code needs to make a decision. How can we accurately target ‘userId=’ without being misled by ‘userIdInfo=’? That’s where our trusty secret weapon — Regular Expressions (or RegEx) — steps in to save the day.
Let’s see the power of RegEx:
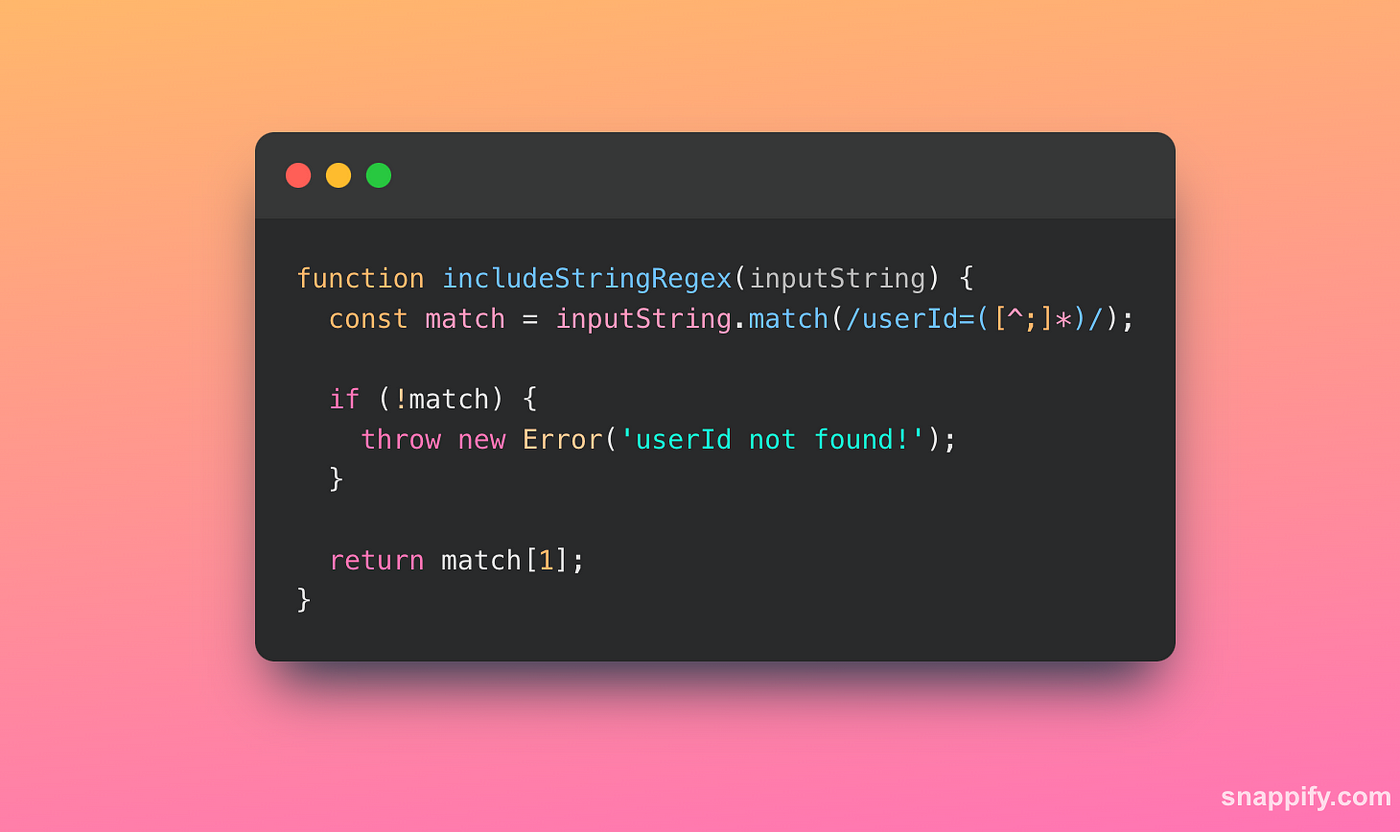
In this function, we’re using a RegEx pattern to search for ‘userId=’ followed by any characters that aren’t a semicolon. This ensures that we capture the exact value of ‘userId=’, even when ‘userIdInfo=’ is trying to throw us off track.
Let’s run it on our tricky string:
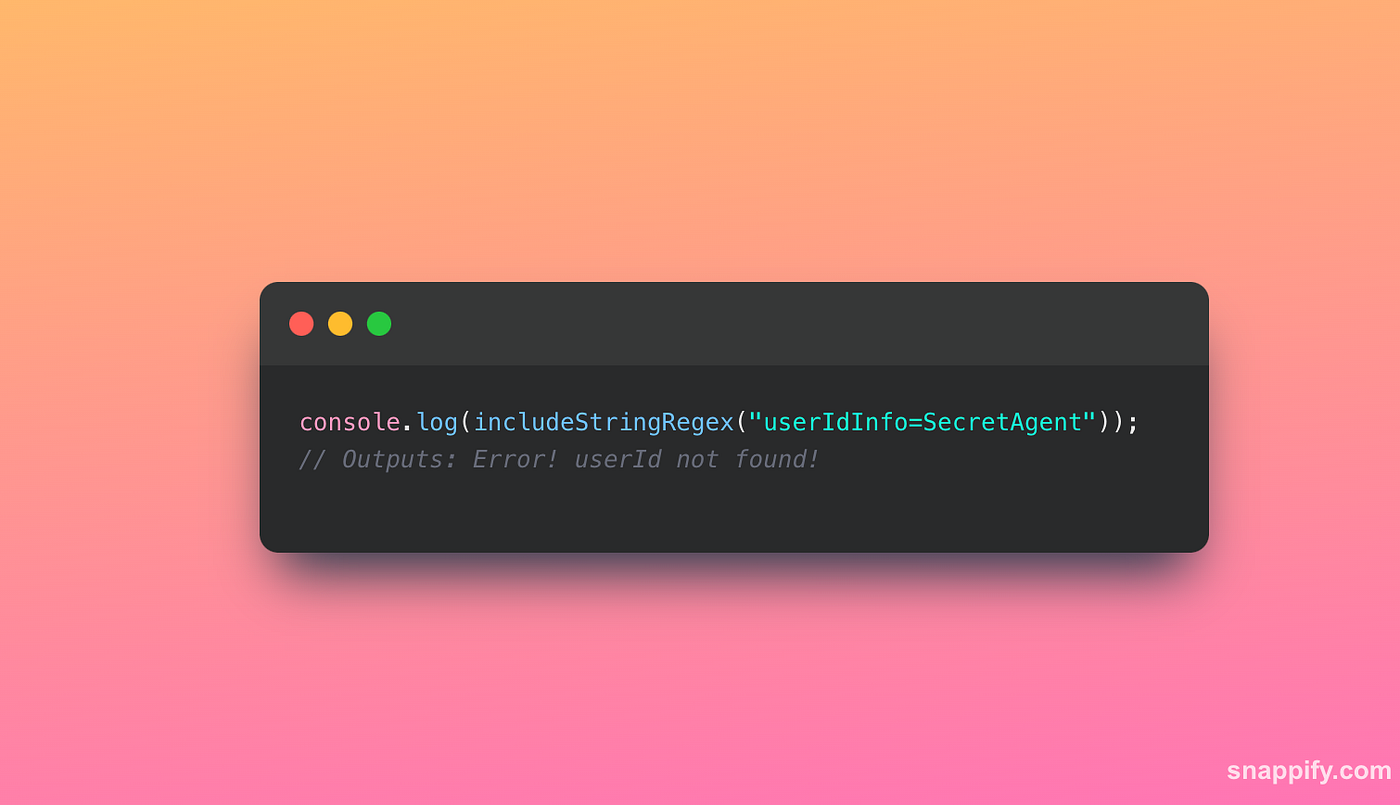
Lo and behold, our clever code detective doesn’t fall for the decoy and successfully uncovers the actual ‘userId’. This resolution truly underscores the versatility of RegEx, and the importance of picking the right tool for the task at hand!
And that’s a wrap, folks! We’re done, this time for real.
Well, almost.
We’ve covered the basics, but now let’s delve into the trenches with a real-life, complex example.
Regular Expressions can be a powerful tool to match patterns in strings, but they can become quite complex, especially when attempting to match something as varied as a URL. URLs has many forms and structure, depending on the level of validation you need, the regular expression can get quite complicated.
Here is an example of a regular expression that matches URLs from any domain, subdomain, and domain endings like .com, .co, .org.uk:

Lets take this scary this and try to break in down:
(http[s]?:\/\/)? matches the “http://” or “https://” at the start of the URL (if present).
([w]{3}\.)? matches the “www.” part of the URL (if present).
([\w-]+(\.[\w-]+)+) matches the domain name, including subdomains and the top level domain (.com, .org.uk, etc.).
(\/[\w-;,@?&%=+\/$_.-]*)? matches the rest of the URL, including the path, parameters, etc.
This regex pattern, while effective, has potential performance implications due to its complexity and the need for backtracking. Each group (indicated by parentheses) and each optional character (indicated by the question mark) adds to the complexity. The regex engine needs to check each possibility, which can be time consuming.
Furthermore, the more complex the regular expression, the harder it is to read and maintain. Someone else looking at this regular expression may struggle to understand what it’s matching, which could be problematic in a team setting.
So far our quest for the right method has been largely about finding specific words within a string. However, things aren’t always so straightforward in the programming realm.
Often we may need to search for variations of a word or specific patterns within a string. This is where methods like includes() and indexOf() start to lose their shine. As powerful and handy as they may be, these methods can quickly become unwieldy and overly complex when dealing with a multitude of variations and patterns.
And while RegEx might seem like the perfect fit for such a task, we have already unveiled its shortcomings. This leads us to question — is there a better way to handle this kind of a complex scenarios? And if so, what might it be? Let’s keep exploring to find out.
For instance, if you run this regex pattern on a very long string, especially one that doesn’t contain a URL, the regex engine could take a considerable amount of time trying to find a match.
In cases where performance is a concern and RegEx become too complex, since we know what pattern we are looking for, we can consider other methods to validate or parse URLs. For instance, we can use the built-in URL API in JavaScript, or split the URL into parts and validate each part separately.
The URL API is a built-in interface in JavaScript that provides methods and properties for working with URLs. You can use it to parse a URL and access its different parts. This is generally more efficient than a regular expression for complex URLs, and it has the added benefit that we understand what we are trying to validate.
Here’s an example:
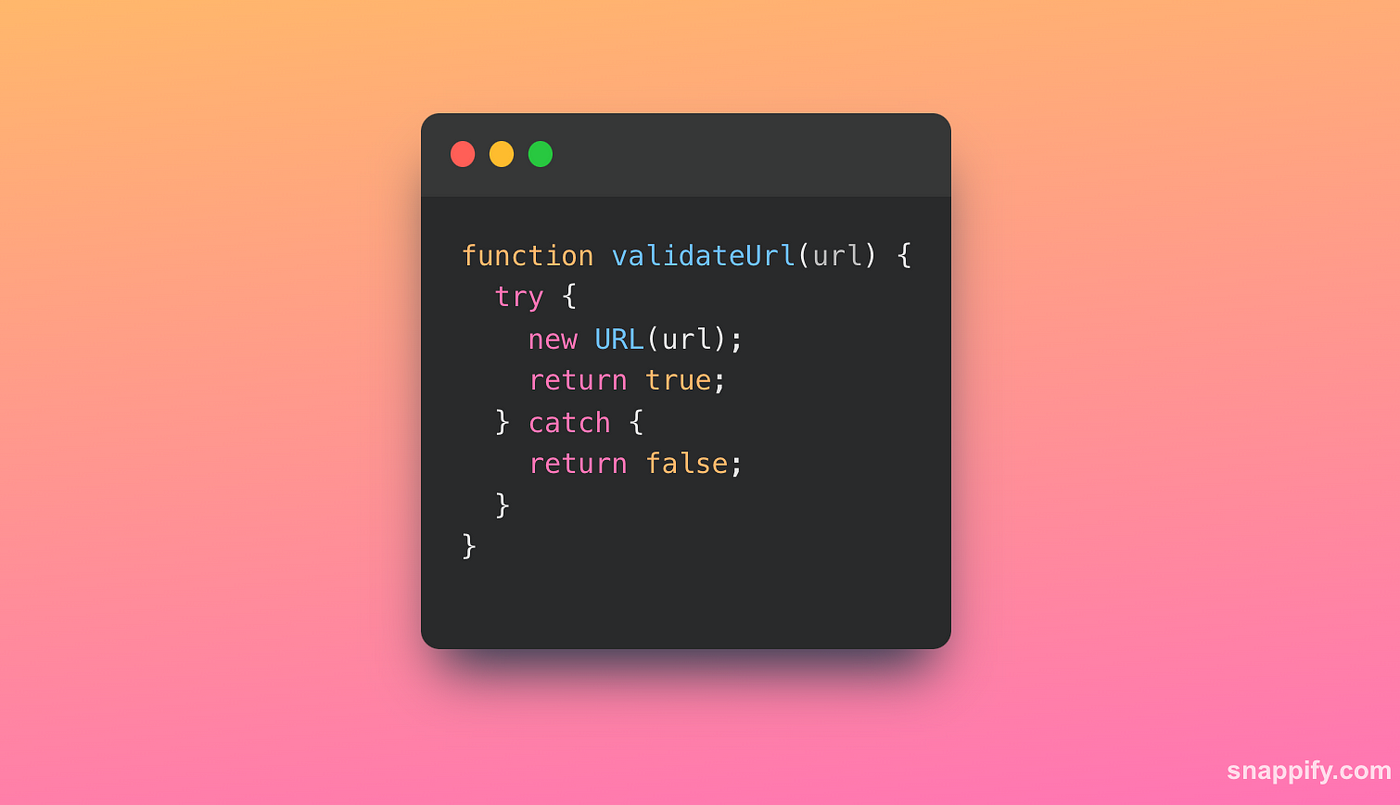
This function attempts to create a new URL object from the given string. If the string is a valid URL, the function returns true;
Splitting the URL into parts
Another approach would be to split the URL into parts and validate each part separately. This gives you more control over the validation process and can be more efficient than a single complex regular expression.
For example, you could separate the protocol (http/https), domain (actual address), and path, and validate each part, if any part fail to validate this is will not be considered a valid URL.

This function splits the URL by slashes and dots, and then validates each part. This gives you more granular control over the validation process, and it’s easier to read and maintain than a complex regular expression.
Conclusion

In the end, programming rarely has a universally applicable answer. Understanding your issue, being familiar with your resources, and coming to an informed choice are all important. The phrase “right tool for the job” comes to mind.
This article aimed to shed some light on the nuanced art of selecting string-searching methods in JavaScript. But the underlying principle — being adaptable and choosing wisely based on context — is universally applicable in software development. And that’s the real takeaway here. So go forth, armed with your array of coding tools and the wisdom to use them judiciously, ready to tackle your next coding challenge!

